本文章已过时
这篇博客是我对 hack 进学校教务系统的一个过程总结,详细代码已经放在 GitHub 上,需要的自取 教务系统自动化工具
Table of contents
验证码
打开网站 http://jwxs.hhu.edu.cn/ 直接重定向到了登录页面 http://jwxs.hhu.edu.cn/login
面临的第一个问题就是验证码。
获取验证码图片
打开浏览器的开发者工具,刷新页面,可以发现验证码的路径为 http://jwxs.hhu.edu.cn/image/captcha.jpg
我们先写一小段代码把这张图片下载下来
prefix = 'http://jwxs.hhu.edu.cn/'captcha_url = prefix + 'img/captcha.jpg'src = 'captcha.jpg'response = requests.get(captcha_url)file = open(src, 'wb')file.write(response.content)file.close()比如下面这张图片

接下来就是进行文字识别了
识别验证码内容
这里我查阅资料发现需要使用 tesseract 这个OCR引擎,安装半天终于安装好了之后发现识别结果基本不太准,我又找到了一个名字很特殊的 python 库 ddddocr。我抱着玩一玩的心态安装且尝试着识别了几张图片,发现效果还行。
ocr = ddddocr.DdddOcr(show_ad=False)with open(src, 'rb') as f: img_bytes = f.read()res = ocr.classification(img_bytes)print('captcha:', res)在我尝试了很多张图片后,我发现由于图片中的干扰线,识别成功率其实不是很高,于是我就继续查阅资料,试图图片进行降噪处理。
图片降噪处理
在经历了多次失败之后,我总结了一下原因:
-
网上的解决方案并不一定适合所有种类的验证码,比如说有的验证码只是背景有噪点,或者有很多细线,而我们这个是一条和内容差不多的黑线,按照网上的一些方法降噪很可能连着内容本身也去掉了
-
仔细观察验证码,可以发现都是画面主题是红色,加上黑粗线,那我们只需要将图片中的黑色或者接近黑色的像素块改成白色不就行了?
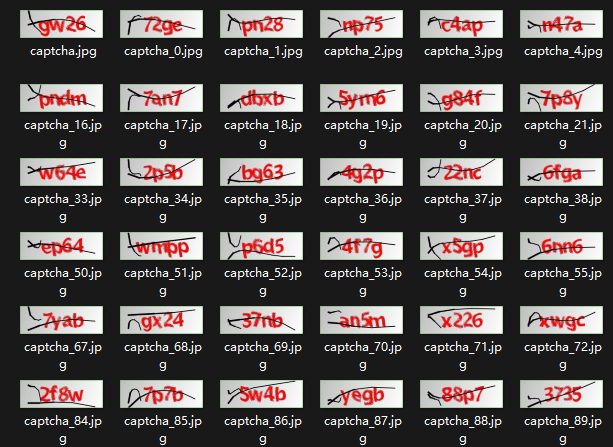
又是一轮新的尝试,最终发现下面这样处理效果最好
def process_data(src, dst): img = Image.open(src) w, h = img.size for x in range(w): for y in range(h): r, g, b = img.getpixel((x, y)) low, up = 50, 256 if r == 0 and g == 0 and b == 0: img.putpixel((x, y), (255, 255, 255)) if r in range(low) and g in range(low) and b in range(low): img.putpixel((x, y), (255, 255, 255)) if r in range(low, up) and g in range(low, up) and b in range(low, up): img.putpixel((x, y), (255, 255, 255)) img.save(dst)
if __name__ == "__main__": ... process_data(src, dst) ocr = ddddocr.DdddOcr(show_ad=False) with open(dst, 'rb') as f: img_bytes = f.read() res = ocr.classification(img_bytes) print('captcha:', res)图片处理前后差别还是很大的

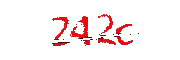
终于是解决了验证码的问题,接下来才是正题
自动登录
如果我们什么都不输入,直接点击登录按钮时,我们会发现多了一个请求 POST http://jwxs.hhu.edu.cn/j_spring_security_check
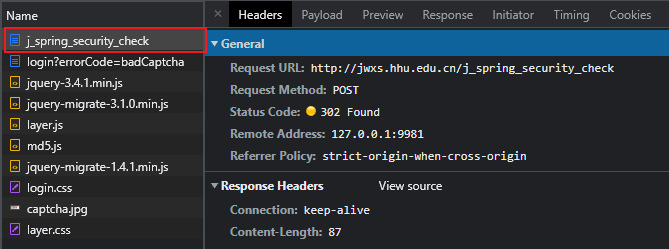
检查表单元素就可以发现是登录时提交给系统的信息,包括三个字段。
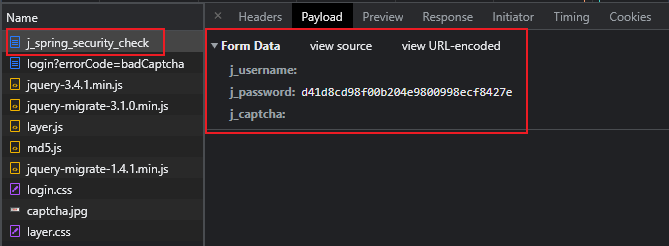
这时我还没注意到没输密码时提交的密码其实不为空,这个点坑了我很久
写一个 Request 类,定义登录的方法
...class Request(object): def __init__(self, username, password): self.username = username self.password = password self.session = requests.Session() self.headers = ... self.cookies = self.session.cookies
def captcha(self): src = 'captcha.jpg' dst = 'captcha_p.png' response = self.session.get(captcha_url) file = open(src, 'wb') file.write(response.content) file.close() res = captcha_code(src, dst) return res
def login(self): post_data = ... self.session.post(post_url, post_data, headers=self.headers) response = self.session.get(index_url, headers=self.headers, cookies=self.session.cookies) soup = BeautifulSoup(response.text, 'lxml') name = soup.find('title').string if name == 'URP综合教务系统首页': print('login success') print('JSESSIONID:', self.session.cookies.get('JSESSIONID'))
if __name__ == "__main__": request = Request(USERNAME, PASSWORD) request.login()我们来运行,奇怪,命令行并没有打印 login success
检查一下验证码识别结果?并没有问题。看一下HTML里的表单?都是对应上的。
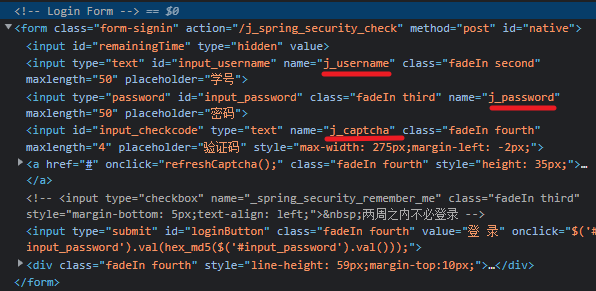
学号对应 j_username,密码对应 j_password,验证码对应 j_captcha,不应该有问题啊。这个 hex_md5 是什么东西。
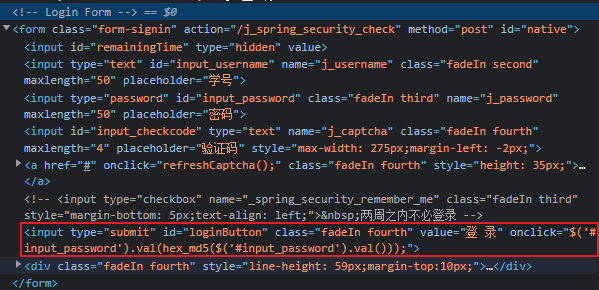
终于发现了不填密码提交表单中密码也是有内容的。在提交表单之前对密码字段进行了 md5 加密,寻找源文件发现了一个名为 md5.js 的文件。搜索 convert js to python,发现了 Js2Py 这个python库,相当方便
这时给我们的代码加上这个加密函数即可
def login(self): post_data = { 'j_username': self.username, 'j_password': md5.hex_md5(self.password), 'j_captcha': self.captcha(), } self.session.post(post_url, post_data, headers=self.headers) response = self.session.get(index_url, headers=self.headers, cookies=self.session.cookies) soup = BeautifulSoup(response.text, 'lxml') name = soup.find('title').string if name == 'URP综合教务系统首页': print('login success') print('JSESSIONID:', self.session.cookies.get('JSESSIONID'))这时可以顺利进入系统了
captcha: xxxxlogin successJSESSIONID: abcMTh7Thb9p4ef4DZ2my爬取需要的数据
这不是线下上课了嘛,上完课想找个空教室自习成了个不是那么容易的事,除了自己找还可以上教务查询,但是每次登录教务还要输验证码,登录状态还会很快失效,就把这件事变成了简单但很重复的事情。
首先定位到 空闲教室查询主页,随便点击一个教学楼,可以发现浏览器向 http://jwxs.hhu.edu.cn/student/teachingResources/freeClassroom/today 发送了一个 POST 请求,请求头里的 Content_type 是 application/x-www-form-urlencoded。
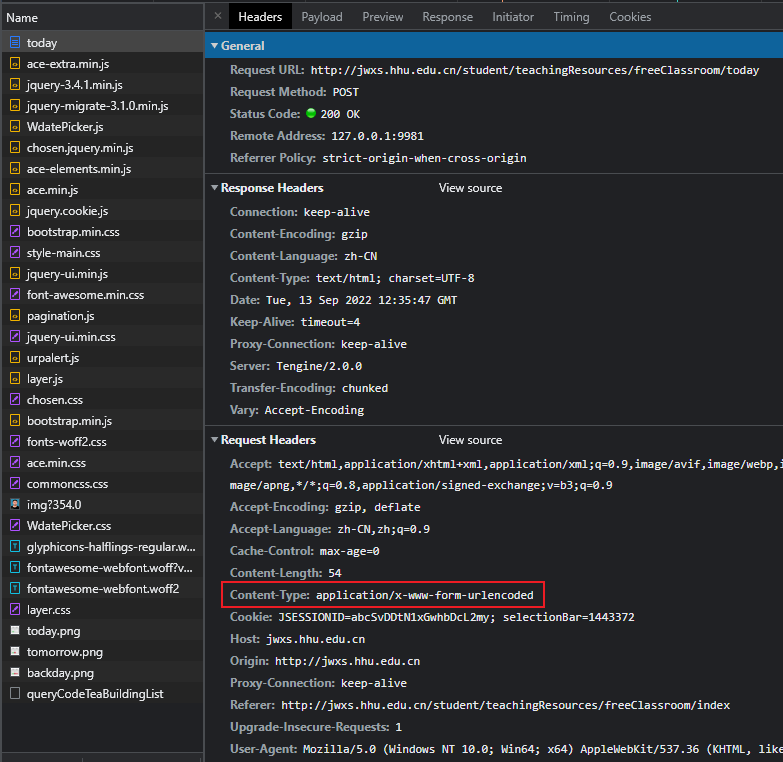
查看表单会发现,有两个信息,应该是教学楼编号和校区号
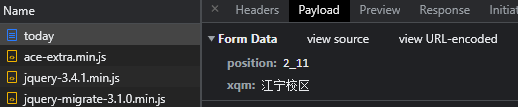
我们往下看可以看到还多出来一个 queryCodeTeaBuildingList ,点击进去发现确实如此
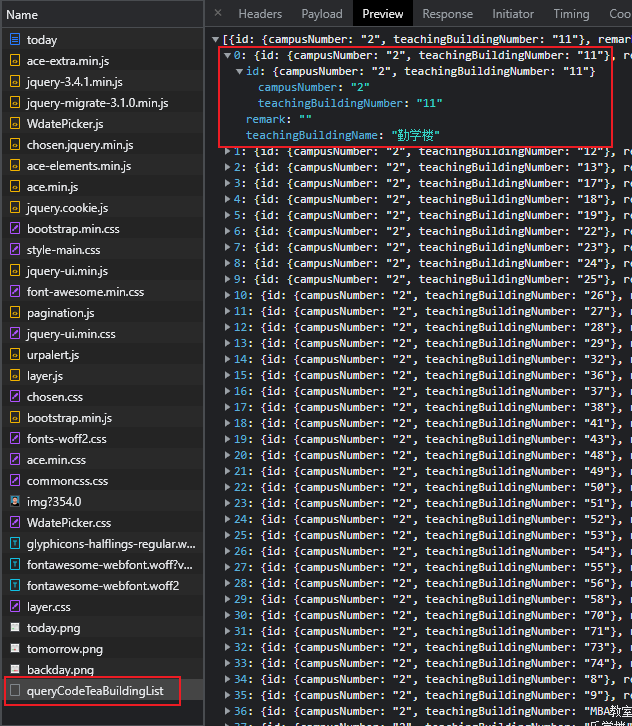
江宁校区的勤学楼的编号是 2_11
如果我们试图直接获取当前页面也就是 http://jwxs.hhu.edu.cn/student/teachingResources/freeClassroom/today 的内容会发生什么?
答案当然是得不到我们想要的结果,原因在于 application/x-www-form-urlencoded
application/x-www-form-urlencoded: 数据被编码成以 ’&’ 分隔的键 - 值对,同时以 ’=’ 分隔键和值。非字母或数字的字符会被 percent-encoding: 这也就是为什么这种类型不支持二进制数据 (应使用 multipart/form-data 代替).
查看网页源代码会发现,这里使用了动态渲染技术,简单说就是 JSP
JSP(全称Jakarta Server Pages,曾称为JavaServer Pages)是由Sun Microsystems公司主导创建的一种动态网页技术标准。JSP部署于网络服务器上,可以响应客户端发送的请求,并根据请求内容动态地生成HTML、XML或其他格式文档的Web网页,然后返回给请求者。JSP技术以Java语言作为脚本语言,为用户的HTTP请求提供服务,并能与服务器上的其它Java程序共同处理复杂的业务需求。
那我们怎么办呢,其实还有办法,我们注意看自定义选项
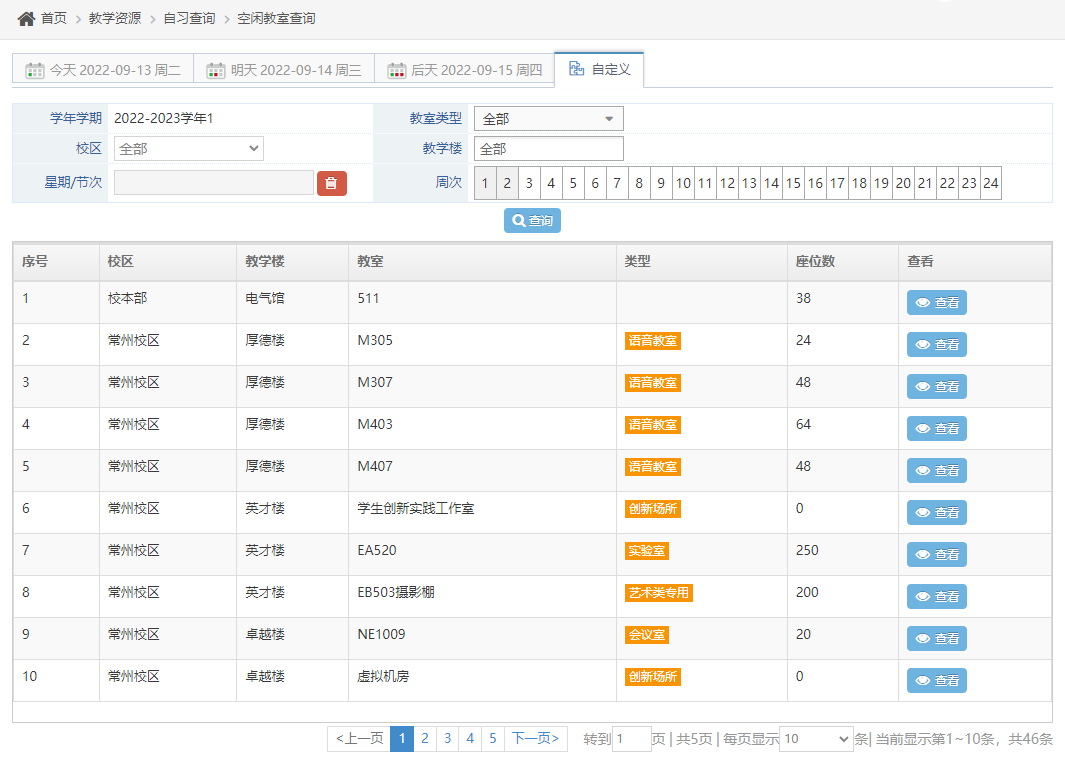
我们有很多选择来进行查询,而查询结果在下面的二维表格里,不妨直接点一下搜索,可以看到多出来的 search
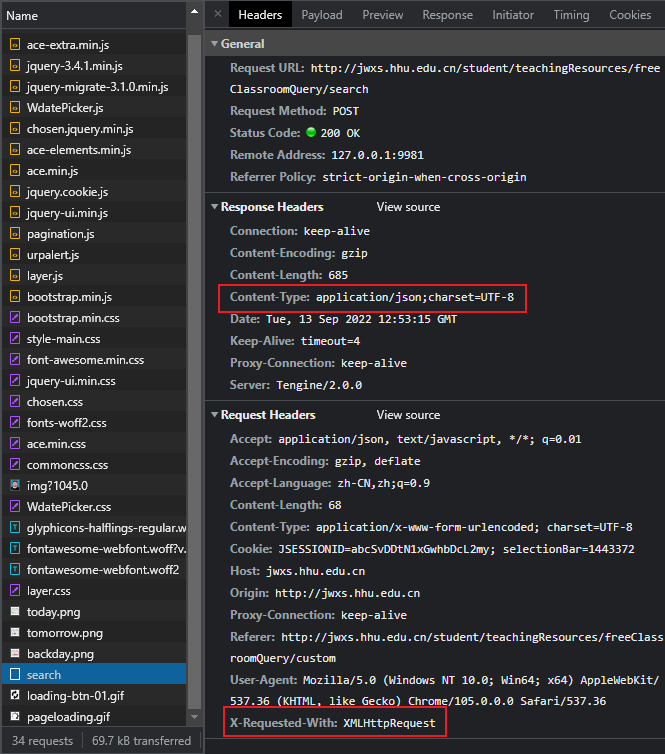
注意看请求头和效应头里的 Content-Type,服务器返回了 JSON 格式的数据,如果做过前后端分离的项目对这个是不是很熟悉?我猜测现在的教务系统不全是 JSP,也有这种部分前后端分离的接口。
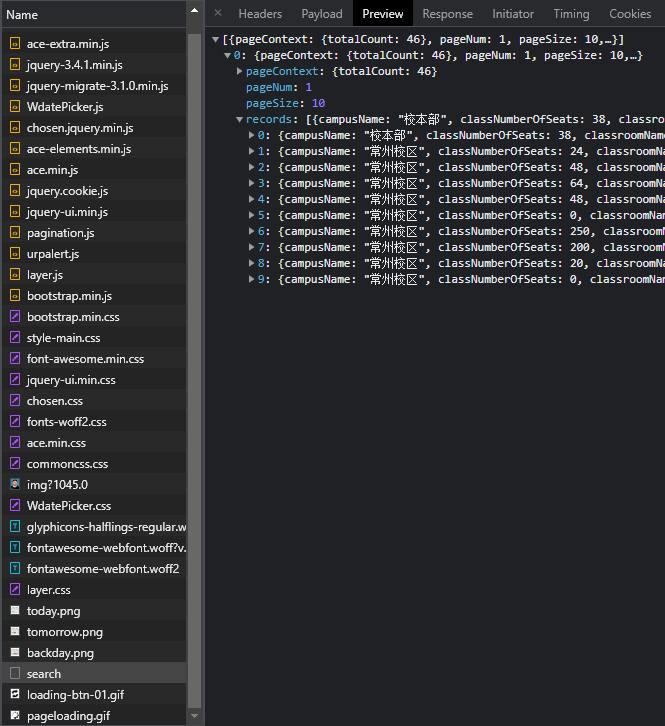
对与前后端的数据应该很好解析,在贴代码之前我们先来分析一下表单元素
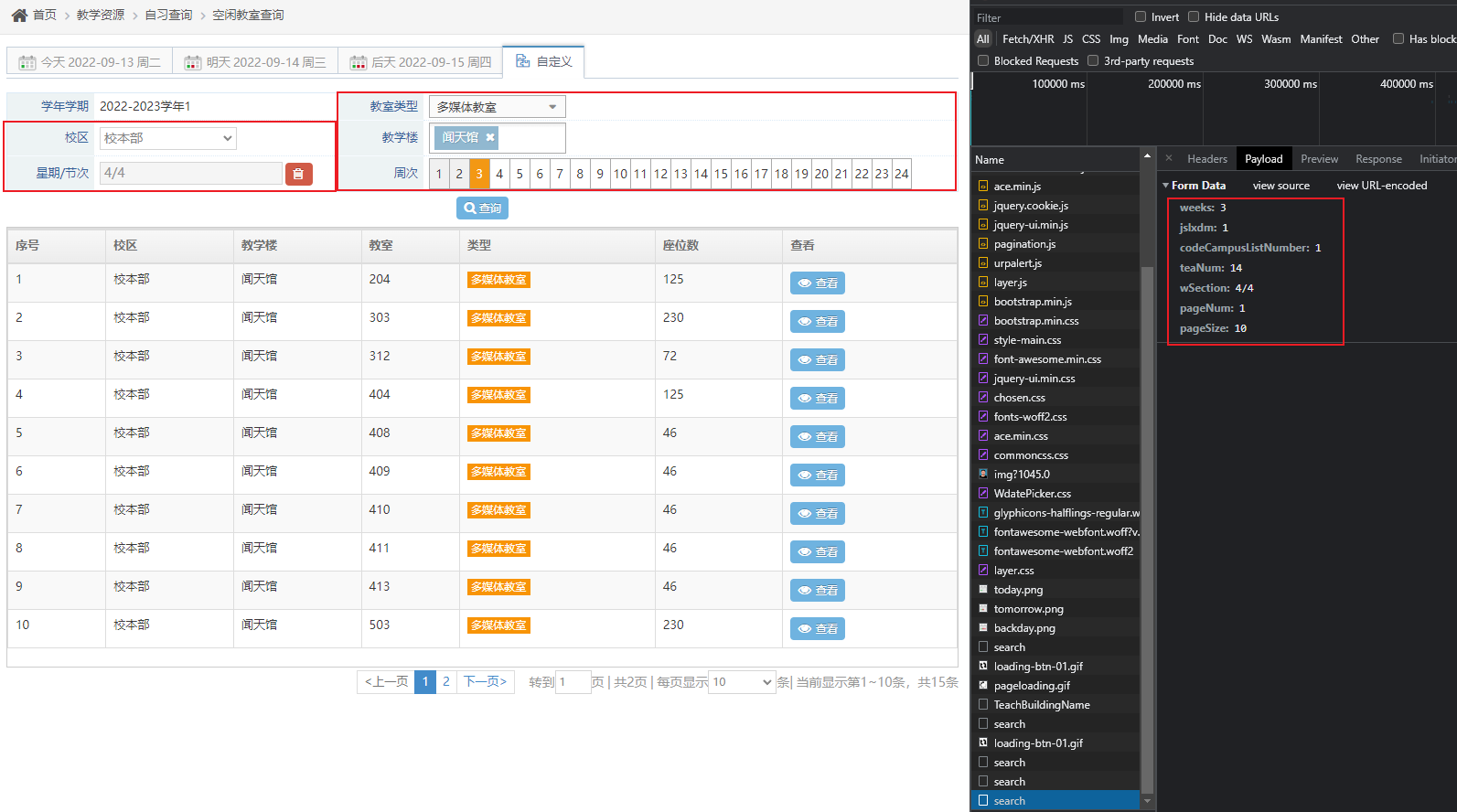
- weeks - 周数
- jslxdm - 教室类型
- codeCampusListNumber - 校区编号
- teaNum - 教学楼编号
- wSection - 星期/节次
- pageNum - 页数
- pageSize - 每页数量
知道了每个字段的含义,再加上查询得到的教学楼编号等等,即可查询到某天某节某个教学楼的空闲教室情况。
def search_free_classroom(self, query_param): headers = ... response = self.session.post(query_url, data=query_param, headers=headers, cookies=self.session.cookies) data = response.json()[0]['records'] sets = [] for i in range(len(data)): val = data[i]['classroomName'] sets.append(val) logging.debug(sets) return sets
if __name__ == "__main__": request = Request(USERNAME, PASSWORD) request.login() param = { 'weeks': 3, 'jslxdm': 1, 'codeCampusListNumber': 1, 'teaNum': 14, 'wSection': 4/4, 'pageNum': 1, 'pageSize': 10, } request.search_free_classroom(param)基本想法完成了,但是,比较困扰我的一点是,查询到的数据该以什么样的方式存储起来,这一点可能还需要我好好想想,或许会写个接口来传输数据,然后写个 App 方便查询?还不太确定。
以上。